The administration disagreed with the jobs count released by the Bureau of Labor…
Statistics
More than mean, median, and mode.
-
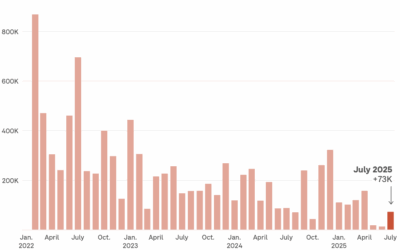
Commissioner of Labor Statistics fired, because labor statistics were not to president’s liking
-
Federal data more at risk, a report from American Statistical Association
The American Statistical Association released a report last year on the growing challenges…
-
Odds against a sports betting king
For New York Times Magazine, Devin Gordon profiled popular oddsmaker Mazi VS, a…
-
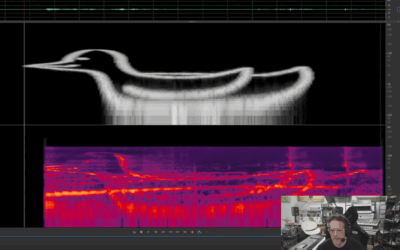
Storing PNG image data in a bird’s song
Birds have a strong ability to learn and mimic sounds. So, Benn Jordan…
-
Facial recognition app linked with government data
For 404 Media, Joseph Cox describes an app, Mobile Fortify, that ICE officers…
-
ICE to access private data from Medicaid records
For the Associated Press, Kimberly Kindy and Amanda Seitz report:
The database will… -
Down with measurements
For WaPo Opinion, Catherine Rampell describes this year’s string of resource reductions for…
-
Errant data led to errant prosecution of British postal workers
Thousands of workers were wrongfully accused and prosecuted in the early 2000s, because…
-
IRS building a system to share private data with ICE
For ProPublica, William Turton, Christopher Bing, and Avi Asher-Schapiro report on a blueprint…
-
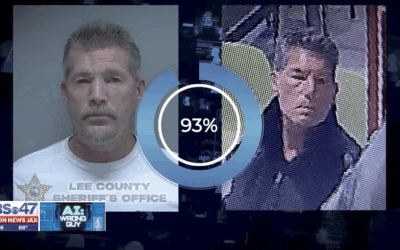
Misidentified by facial recognition and arrested
In Jacksonville, Florida, police arrested a man because AI facial recognition classified his…
-
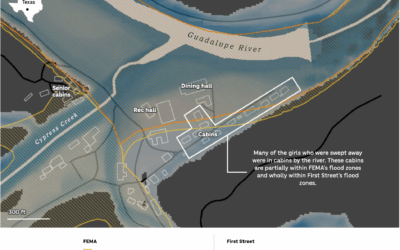
FEMA flood risk vs. more comprehensive estimates for Camp Mystic
Risk estimates change by statistical model and what that model accounts for. The…
-
DOGE goes for farmers’ financial and personal data
For NPR, Jenna McLaughlin breaks down DOGE access to sensitive USDA data and…
-
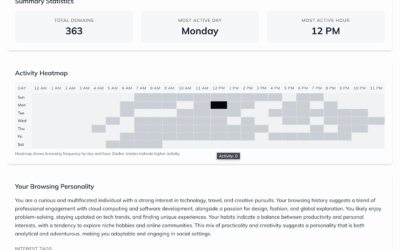
Matching potential partners based on browser history
Ideally, your romantic partner for life has similar interests, hopes, dreams, and browsing…
-
Autism definition changed, which led to rise in diagnoses
Allen Frances, a psychiatrist who chaired the group to update the Diagnostic and…
-
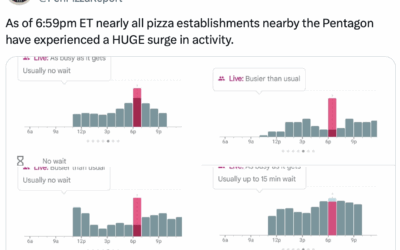
Pizza activity spikes just before reports of Israel attacking Iran
The Pentagon Pizza Report tracks pizza place activity near the Pentagon. From the…
-
Airlines sell passenger flight data to Customs and Border Protection
While there are laws in the U.S. to protect some of your privacy…
-
Reduced sampling for Consumer Price Index estimates
The Bureau of Labor Statistics announced a reduction in data collection to put…
-
Magnus Carlsen chess match against the wisdom of crowds ends in a draw
Chess grandmaster Magnus Carlsen played against 143,000 people in a single game. The…
-
Professor who studied honesty loses tenure over faked data
A couple years ago, Harvard professor Francesca Gino was accused of faking data,…
-
Survey microdata for free
Downloading survey microdata from public resources can be tricky. Sometimes the documentation is…
Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →









